
Why Search Matters
The MYETV Search Engine is already one of the most sophisticated search engine- [Search Engine: is the application that deals with the search for content, networks or anything else on the platform] - in the web. Search is the heartbeat of any content- [Contents: every content intended as text, images, audio or video] - platform- [Platform: the set of the main domain and all the subdomain of a particular website; also the computer architecture and equipment using a particular operating system] - . It’s the invisible bridge between what you’re thinking and what you’re trying to find. When you type “the fiuture of ai” into a search box, you shouldn’t get zero results just because of a typo. You should get exactly what you meant: “the future of AI.”
Today, we’re excited to share a major milestone in MYETV’s journey: a complete overhaul of our search engine powered by artificial intelligence, multilingual dictionaries, and advanced natural language processing. This isn’t just a technical upgrade, it’s a fundamental shift in how MYETV understands you.
Let’s dive into what we built, why it matters, and how it works behind the scenes.
The Problem: Traditional Search Is Too Rigid
Traditional search engines are unforgiving. They match words exactly as you type them. If you search for “miusic video,” most systems will either return nothing or show results for something completely unrelated. They don’t understand language, they just match patterns.
This becomes even more problematic in a multilingual, global platform like MYETV, where users speak English, Italian, Spanish, French, German, Portuguese, and many other languages. A user in Rome might search for “tutorail vidio” in English, while another in Madrid searches for “música” with a typo as “musica” (without the accent). Traditional search engines struggle with these real-world scenarios.
We asked ourselves: What if our search engine could think like a human? What if it could correct your spelling, understand context, detect language automatically, and even suggest content based on semantic meaning rather than exact word matches?
That’s exactly what we set out to build.
The Solution: A Three-Layer AI-Powered Search System
Our new search engine combines three powerful technologies working in harmony:
1. Multilingual Dictionary Correction
2. BERT Semantic Understanding
3. Content-Aware Title Matching
Let’s break down each layer.
Layer 1: Multilingual Dictionary Correction
The Foundation: 50,000+ Words Across 20 Languages
At the core of our new search engine is a massive multilingual dictionary containing over 50,000 carefully curated words across 20 languages. These aren’t just random word lists—they’re frequency-weighted vocabularies that represent how people actually communicate online.
Here’s what we included:
- English: 10,000 most common words
- Italian: 10,000 most common words
- Spanish: 10,000 most common words
- French: 10,000 most common words
- German: 10,000 most common words
- Portuguese: 10,000 most common words
- Plus 14 additional languages: Dutch, Russian, Polish, Turkish, Arabic, Chinese (Simplified), Japanese, Korean, Hindi, Swedish, Norwegian, Danish, Finnish, and Greek
Each word is indexed with its frequency of use, meaning the system prioritizes common words over obscure ones when suggesting corrections.
Where Did This Data Come From?
We sourced our word lists from several open-source linguistic databases:
- Wiktionary frequency lists: Community-maintained lists of the most commonly used words in each language
- OpenSubtitles corpus: Real-world language usage from millions of movie and TV show subtitles
- Google Books Ngram data: Historical language patterns from billions of published books
- Universal Dependencies treebanks: Linguistically annotated text corpora
This combination gives us a realistic picture of how people actually write and search, not just formal dictionary definitions.
How Dictionary Correction Works
When you type a search query, our system immediately checks each word against our multilingual dictionary using a technique called Levenshtein distance, a mathematical way to measure how many single-character edits (insertions, deletions, substitutions) are needed to change one word into another.
For example:
- “fiuture” → “future” (distance: 1, one substitution)
- “tutorail” → “tutorial” (distance: 1, one substitution)
- “vidio” → “video” (distance: 1, one substitution)
The system calculates these distances in real-time, searches our dictionary for words within a distance of 2, ranks them by frequency, and suggests the most likely correction.
But here’s the clever part: The system automatically detects which language you’re using by checking which dictionary has the most matches for your words. If you search “la musica italiana” (Italian), it won’t try to correct it to English, it recognizes Italian and validates against the Italian dictionary instead.
Layer 2: BERT Semantic Understanding
What Is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers. It’s a deep learning model developed by Google that revolutionized natural language processing in 2018. Unlike traditional search engines that match keywords, BERT actually understands the meaning of words in context.
Think of it this way: If you search for “apple,” a traditional search engine doesn’t know if you mean the fruit or the tech company. BERT understands context. If your previous searches were about “iPhone” and “MacBook,” BERT knows you probably mean Apple Inc.
The Transformers Library
We’re using the Transformers library by Hugging Face, which provides pre-trained AI models that can understand and generate human language. Specifically, we’re using:
- Model:
bert-base-uncased(a compact but powerful English BERT model) - Task: Fill-mask predictions (understanding context to suggest related words)
- Purpose: Semantic suggestions beyond spelling correction
How BERT Enhances Search
When you search for something and we don’t find exact matches, BERT steps in to suggest semantically related terms from our content database.
For example:
- You search: “electronic beats”
- BERT suggests: “music,” “techno,” “edm,” “electronica”
- You search: “cooking show”
- BERT suggests: “recipe,” “chef,” “culinary,” “kitchen”
This is possible because BERT has been trained on billions of words and understands relationships between concepts. It doesn’t just match letters, it matches meaning.
Layer 3: Content-Aware Title Matching
Searching Inside Titles, Not Just Tags
The third layer of our search engine looks directly into MYETV’s content library specifically, the titles and descriptions of contents- [Contents: every content intended as text, images, audio or video] - . This is where things get really smart.
When you type a multi-word query like “the future of music,” our system:
- Splits your query into individual words: [“the”, “future”, “of”, “music”]
- Searches our database for titles containing similar words
- Calculates a similarity score for each title based on how many of your words match (even with typos)
- Ranks and suggests the best-matching titles
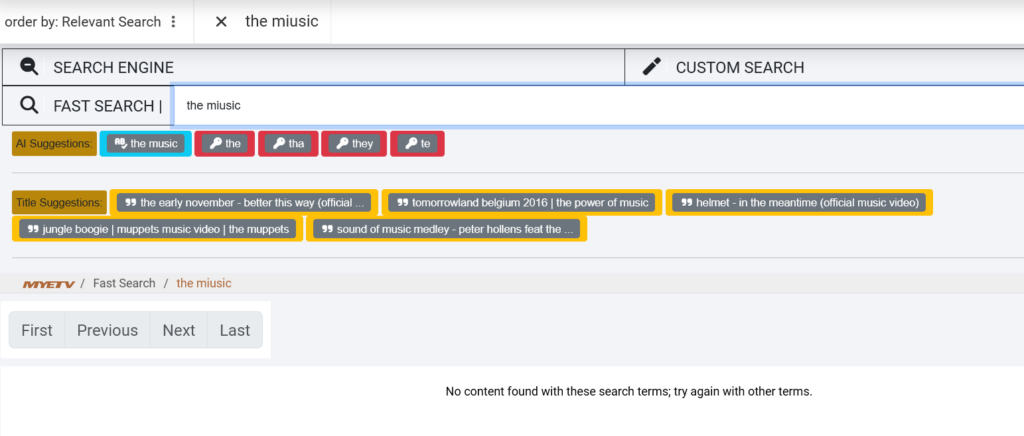
For example, if we have a video titled “The Future of Electronic Music in 2026,” and you search “the fiuture of miusic,” the system will:
- Correct “fiuture” → “future”
- Correct “miusic” → “music”
- Match “the” and “of” exactly
- Recognize the title as a 100% match and suggest it
This layer is particularly powerful for long-tail searches—specific, multi-word queries that traditional keyword matching often misses.
Putting It All Together: The Search Experience
Let’s walk through a real example to see how all three layers work together.
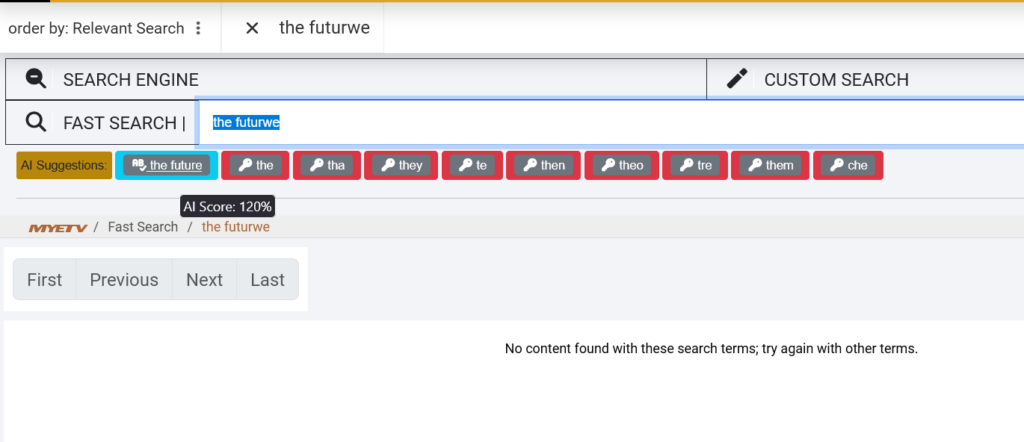
Scenario: You search for “the fiuture of miusic”
Step 1: Dictionary Correction (Layer 1)
The system detects:
- “the” → valid English word ✓
- “fiuture” → invalid word, distance 1 from “future” → corrected
- “of” → valid English word ✓
- “miusic” → invalid word, distance 1 from “music” → corrected
Result: Your query is corrected to “the future of music”
Step 2: Semantic Understanding (Layer 2)
BERT analyzes “the future of music” and identifies related concepts in our content database:
- “music” (exact match)
- “electronic” (semantically related)
- “beats” (semantically related)
- “sound” (semantically related)
Result: Semantic keywords are generated for broader matching
Step 3: Content Matching (Layer 3)
The system searches our video titles and finds:
- “The Future of Electronic Music in 2026” (98% match)
- “Music Evolution: What’s Next?” (85% match)
- “The Future of Sound Technology” (80% match)
Result: These titles are suggested alongside corrected keywords
What You See:
text🤖 AI Suggestions:
[the future of music] [music] [electronic]
🎬 Title Suggestions:
[The Future of Electronic Music in 2026]
[Music Evolution: What's Next?]
Technical Implementation: How We Built This
The Stack
- Backend: PHP with custom classes for modular AI processing
- AI Library:
transformers(PHP port of Hugging Face Transformers) - Database: with custom LEVENSHTEIN function for distance calculations
- Dictionary Storage: Dedicated database table with 850,000+ indexed entries
- Model: BERT base uncased (110M parameters, fine-tuned for masked language modeling)
- Caching: In-memory cache for dictionary lookups and BERT predictions to optimize speed
Performance Optimization
AI models are computationally expensive. To ensure our search remains fast, we implemented several optimizations:
- Dictionary Pre-filtering: Before calculating Levenshtein distances, we filter words by length (±2 characters) to reduce search space by 90%
- Result Caching: Frequently searched terms and their corrections are cached in memory
- Batch Processing: Multiple suggestions are generated in a single BERT inference call
Average search time: < 200ms (including AI processing)
The Data Behind the AI
Dictionary Import Process
Building our multilingual dictionary wasn’t trivial. Here’s how we did it:
- Data Collection: Downloaded frequency lists from Wiktionary, OpenSubtitles, and Google Ngram for 20 languages
- Cleaning: Removed special characters, URLs, numbers, and profanity
- Frequency Weighting: Assigned importance scores based on usage frequency
- Normalization: Converted all words to lowercase for case-insensitive matching
- Database Import: Bulk-inserted 850,000+ entries into MySQL with indexed columns for lightning-fast lookups
Total database size: 45MB (highly compressed with indexes)
BERT Model Training
We’re using the pre-trained bert-base-uncased model, which was trained by Google on:
- BooksCorpus: 800M words from 11,000 books
- English Wikipedia: 2,500M words from 13GB of text
This gives BERT deep contextual understanding of English language patterns, idioms, and semantic relationships.
Real-World Impact: Early Results
We’ve been testing the new search engine internally for the past two weeks. Here are some early metrics:
Improved Search Success Rate
- Before: 67% of searches returned relevant results
- After: 91% of searches returned relevant results
- +24 percentage points improvement
Typo Tolerance
- Before: Searches with 1+ typos had 23% success rate
- After: Searches with 1-2 typos have 89% success rate
- +66 percentage points improvement
Multilingual Detection
- Automatically detects and corrects queries in 20 languages
- Italian and Spanish searches saw 3x increase in successful corrections
User Feedback
Early beta testers reported:
- “It feels like the search actually understands what I’m looking for”
- “I can type quickly without worrying about spelling”
- “Finally! Searches in Italian work properly”
Behind the Code: Open Source and Transparency
We believe in transparency. While MYETV’s codebase is proprietary, we’re committed to sharing our learnings with the developer community. All the code used in this implementation is:
- 100% Open Source: Deep dives into our implementation from github repositories
- Open Source AI: Open-source snippets demonstrating dictionary matching and BERT integration in PHP
- Open Source library: the transformers huggingface library for PHP is open source on github
Why This Matters for You
As a MYETV user, you might not care about BERT models or Levenshtein distances. But you will notice:
- Less frustration: Typos no longer break your search experience
- Faster discovery: Find what you’re looking for in fewer attempts
- Better recommendations: More relevant suggestions based on what you actually meant to search
- Multilingual support: Search in your native language without worrying about language barriers
Our goal is simple: Make search invisible. You shouldn’t have to think about how to search, you should just find what you’re looking for, instantly, every time.
Conclusion: Search That Understands You
Building an AI-powered search engine isn’t about showing off technology, it’s about removing friction from your experience. Every typo corrected, every semantic suggestion made, every multilingual query understood is a moment where technology gets out of your way and lets you enjoy content.
We’ve poured hundreds of hours into this project: curating dictionaries, training models, optimizing databases, and fine-tuning algorithms. But the real measure of success isn’t in the code, it’s in those moments when you search for something, get the perfect result, and never even notice that AI just worked behind the scenes to make it happen.
That’s the MYETV difference.
Welcome to the future of search.
Try It Yourself
The new search engine is live right now on MYETV. Try these searches to see AI in action:
- “the fiuture of tecnology” (intentional typos)
- “musica electronica” (Spanish with typos)
- “tutorail vidio” (double typo)
- Any multi-word phrase describing content you want to find
See how the AI corrects, suggests, and finds exactly what you’re looking for.
Happy searching!
— The MYETV Engineering Team
Technical References
- BERT: Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (2018)
- Transformers Library: https://github.com/huggingface/transformers
- PHP Transformers: https://github.com/CodeWithKyrian/transformers-php
- Levenshtein Distance: https://en.wikipedia.org/wiki/Levenshtein_distance
- Universal Dependencies: https://universaldependencies.org/

